
")
K-nearest neighbors atau knn adalah algoritma yang berfungsi untuk melakukan klasifikasi suatu data berdasarkan data pembelajaran (train data sets), yang diambil dari k tetangga terdekatnya (nearest neighbors). Dengan k merupakan banyaknya tetangga terdekat.
A. Cara Kerja Algoritma K-Nearest Neighbors (KNN)
K-nearest neighbors melakukan klasifikasi dengan proyeksi data pembelajaran pada ruang berdimensi banyak. Ruang ini dibagi menjadi bagian-bagian yang merepresentasikan kriteria data pembelajaran. Setiap data pembelajaran direpresentasikan menjadi titik-titik c pada ruang dimensi banyak.
A1. Klasifikasi Terdekat (Nearest Neighbor Classification)
Data baru yang diklasifikasi selanjutnya diproyeksikan pada ruang dimensi banyak yang telah memuat titik-titik c data pembelajaran. Proses klasifikasi dilakukan dengan mencari titik c terdekat dari c-baru (nearest neighbor). Teknik pencarian tetangga terdekat yang umum dilakukan dengan menggunakan formula jarak euclidean. Berikut beberapa formula yang digunakan dalam algoritma knn.
-
Euclidean Distance
Jarak Euclidean adalah formula untuk mencari jarak antara 2 titik dalam ruang dua dimensi.

-
Hamming Distance
Jarak Hamming adalah cara mencari jarak antar 2 titik yang dihitung dengan panjang vektor biner yang dibentuk oleh dua titik tersebut dalam block kode biner.
-
Manhattan Distance
Manhattan Distance atau Taxicab Geometri adalah formula untuk mencari jarak d antar 2 vektor p,q pada ruang dimensi n.
-
Minkowski Distance
Minkowski distance adalah formula pengukuran antar 2 titik pada ruang vektor normal yang merupakan hibridisasi yang menjeneralisasi euclidean distance dan mahattan distance.
Teknik pencarian tetangga terdekat disesuaikan dengan dimensi data, proyeksi, dan kemudahan implementasi oleh pengguna.
A2. Banyaknya k Tetangga Terdekat
Untuk menggunakan algoritma k nearest neighbors, perlu ditentukan banyaknya k tetangga terdekat yang digunakan untuk melakukan klasifikasi data baru. Banyaknya k, sebaiknya merupakan angka ganjil, misalnya k = 1, 2, 3, dan seterusnya. Penentuan nilai k dipertimbangkan berdasarkan banyaknya data yang ada dan ukuran dimensi yang dibentuk oleh data. Semakin banyak data yang ada, angka k yang dipilih sebaiknya semakin rendah. Namun, semakin besar ukuran dimensi data, angka k yang dipilih sebaiknya semakin tinggi.
A3. Algoritma K-Nearest Neighbors
- Tentukan k bilangan bulat positif berdasarkan ketersediaan data pembelajaran.
- Pilih tetangga terdekat dari data baru sebanyak k.
- Tentukan klasifikasi paling umum pada langkah (2), dengan menggunakan frekuensi terbanyak.
- Keluaran klasifikasi dari data sampel baru.
B. Contoh Aplikasi K Nearest Neighbors
Contoh berikut diambil dari buku "Data Science Algorithms in a Week" yang ditulis oleh Dávid Natingga.
Pada contoh ini, dilakukan klasifikasi suhu udara berdasarkan persepsi seseorang yang bernama Marry. Adapun klasifikasi suhu udara terdiri dari 2 persepsi yaitu Panas dan Dingin. Persepsi ini dapat diukur berdasarkan 2 variabel yaitu temperatur dalam derajat celcius dan kecepatan angin dalam km/h. Diperoleh data berikut,
| Temperatur Udara (ºC) | Kecepatan Angin (km/jam) | Klasifikasi atau Persepsi Marry |
| 10 | 0 | Dingin |
| 25 | 0 | Panas |
| 15 | 5 | Dingin |
| 20 | 3 | Panas |
| 18 | 7 | Dingin |
| 20 | 10 | Dingin |
| 22 | 5 | Panas |
| 24 | 6 | Panas |
Untuk contoh ini terbentuk ruang dimensi 2, yang berisi 2 kriteria yaitu temperatur udara dan kecepatan angin.
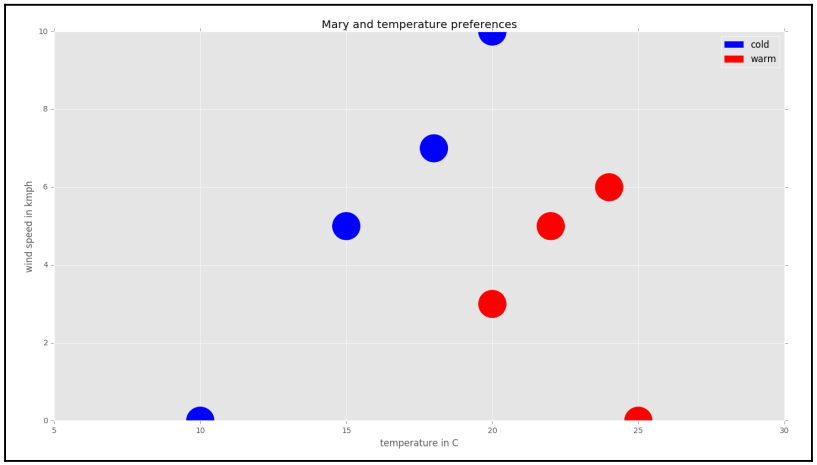
Pada proyeksi di atas sumbu vertikal adalah kecepatan angin, sumbu horizontal adalah temperatur suhu, warna biru adalah dingin, dan warna merah adalah panas.
Dari proyeksi di atas, dapat dilakukan klasifikasi data baru. Misalnya, Bagaimana persepsi Marry saat temperatur udara 16°C dan kecepatan angin 3 km/jam.
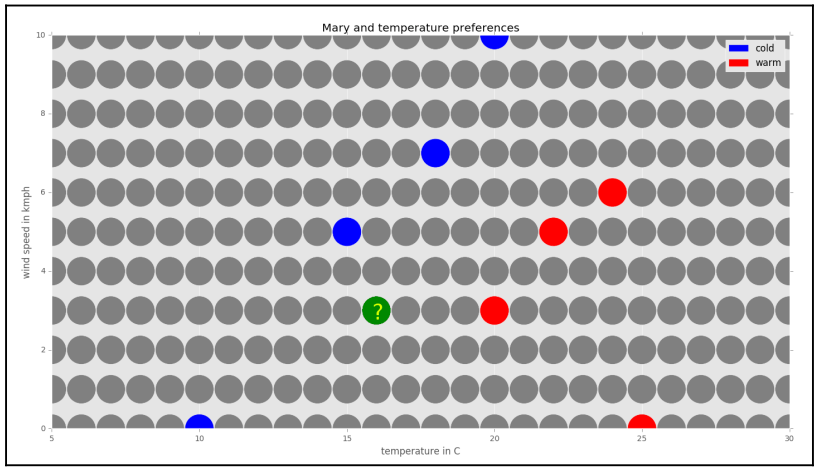
Proses pencarian tetangga terdekat
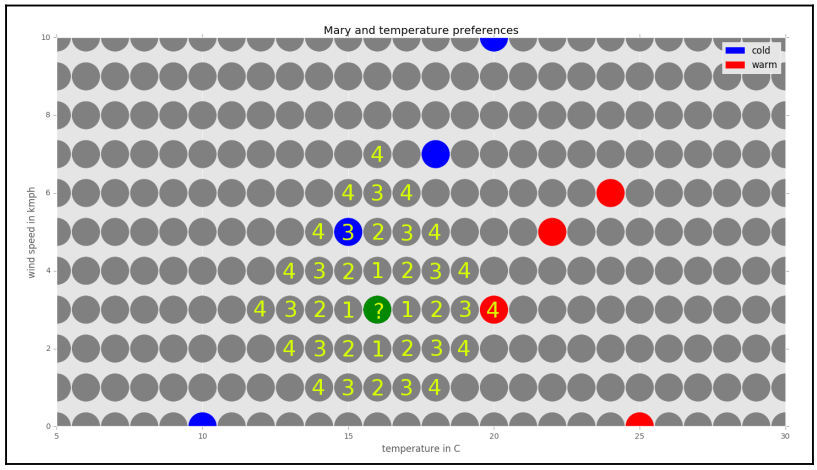
Dapat diketahui tetangga terdekatnya adalah titik c dingin dengan temperatur 15°C dan kecepatan angin 5 km/jam. Jadi berdasarkan pemilihan k = 1, klasifikasinya adalah dingin.
Dengan melakukan proses di atas terhadap semua titik, diperoleh proyeksi klasifikasi berikut.
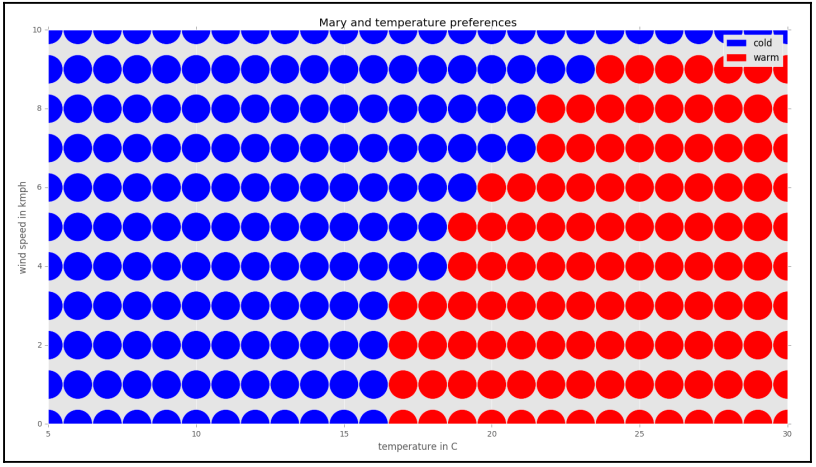
Catatan: Untuk pemilihan k lainnya, hasil klasifikasi ditentukan dengan frekuensi terbanyak. Misalnya k = 3, dengan titik terdekat dingin, panas, dingin. Hasil klasifikasi data baru tersebut adalah dingin.
Baca juga tutorial lainnya: Daftar Isi Machine Learning
Sekian artikel Pengertian dan Cara Kerja Algoritma K-Nearest Neighbors (KNN). Nantikan artikel menarik lainnya dan mohon kesediaannya untuk share dan juga menyukai halaman Advernesia. Terima kasih…




")

Selamat malem kak. Metode wknn itu kan pengembangan dari metode KNN. Misalnya kita mempunyai nilai 683 dan kita menghilangkan 5 data menggunakan k tetangga terdekat 3, 5, 7, 9, 11 itu alasannya kenapa ya kak? Minta tolong butuh jawaban alasannya kak🙇
Hai kak Watsiqatut Dianah
Saya baru pertama dengan metode WKNN, untuk algoritma KNN penggunaan k-tetangga terdakat dimaksud untuk menyeleksi data yang mempunyai karakteristik yang hampir sama dengan data yang diujikan. Sehingga selanjutnya dapat ditentukan karakteristik data yang diuji berdasarkan frekuensi terbanyak dari data-data yang hampir sama tersebut.
Semoga bermanfaat 🙂
kak mau tanya lagi gimana caranya menentukan k-tetangga terdekat jika ada data sebanyak 683 dan apakah ada rumusnya untuk menentukan k ? butuh bantuan jawaban
Hai kak Watsiqatut Dianah, untuk penentuan k tetangga terdekat dapat menggunakan "algoritma optimasi". Hal ini dilakukan karena setiap data yang diproses oleh KNN mempunyai spesifikasi k optimal yang berbeda-beda.
Misalnya, Kakak dapat menggunakan k-fold cross validation untuk melihat performa nilai k dalam interval tertentu. Penentuan bisa dilihat dari representasi grafik yang dihasilkan bisa dilihat dari titik minimum error atau pun konvergensi error yang dihasilkan.
Semoga membantu 🙂
assalamu'alaikum kk mau tanya lagi, bagaimana caranya menghitung nilai KNN jika terdapat 2 nilai kosong pada satu baris/atribut ?
Jika data yang diproses merupakan data train dan data nya berjumlah ratusan, secara sederhana ke-dua data dapat dihilangkan. Dengan asumsi, data yang tidak lengkap adalah data yang tidak valid.
Semoga bermanfaat 🙂
kak misalnya kita mempunyai 683 data dan mau dihilangkan 50 data kira2 enaknya pakek k berapa ?
Wa'alaikumus salam kk, sebaiknya gunakan k dalam interval 3-50, lalu lakukan tuning menggunakan k-fold cross validation
Semoga membantu 🙂
kak mau tanya, apa kah bisa metode knn untuk pembelajaran pada santri pesantren
Hai kak Achmadsainur,
Pembelajaran pada santri pesantren, maksudnya bagaimana kak?
saya ambil judul skripsi data mining menggunakan metode kkn tentang nilai hasil belajar santri nah itu bisa gak yah kak?
Bisa kak Achmadsainur, tapi menurut saya hasil belajar itu lebih baik dimodelkan dalam bentuk fungsi linier, karena variabelnya jelas dan dapat diukur secara langsung.
Semoga bermanfaat 🙂
untuk alur sistemnya Itu kira" bagusnya gmana ya kak, gw sih pake data santri pesantren nah, untuk bagusnya gmna ya kak? mohon bimbingannya dong kak,
Jika kakak menggunakan KNN, secara fundamental ini merupakan algoritma klasifikasi. Sehingga harus ditentukan output data merupakan nilai diskrit yang telah ada pada data, misalnya A, B, C, D, E (Data harus memuat output tersebut). Nah langkah selanjutnya susun data menjadi state space matriks output = kkn(input). Proses pembelajaran akan disesuaikan dengan model KKN yang dibuat sehingga dapat menghasilkan output yang diharapkan.
Semoga bermanfaat 🙂
Kak saya punya judul..
Implementasi alghoritma knn pada pengukuran tingkat kemagangan biji kopi arabika.
Pertanyaanya apa bisa menggunakan metode knn?
Apa aja aplikasi yang di butuhkan untuk melakukan pengolah datanya?
Menrut kaka apa tujuan dengan judul di atas?
Hai kak Ilzam Munasa, menurut saya kasus kematangan kopi tersebut sangat cocok dengan metode knn.
Untuk pengolahan datanya mungkin dapat menggunakan image processing(warna, bentuk), atau variabel lain misalnya ukuran buah, umur buah.
Semoga bermanfaat 🙂
Kak saya mau bertanya, untuk klasifikasi dengan banyak kelas apakah bisa menggunakan knn? contohnya seperti terdapat 5 kelas dan 450 data dan 24 fitur kak. itu cara nya bagaimana ya kak jika terdapat banyak kelas? minta tolong kak bantu jawabannya .
Hai, kak karin
Menurut saya itu bisa dilakukan, knn akan mengolah data dalam ruang R^24. Fitur itu Variabel kan?
cara menetukan 5 kelas dari knn sendiri bagaiamana kak?
Jumlah kelas ditentukan oleh data train dibagian outputnya, nanti data train jika divisualisasikan akan kelihatan kelas yang dibentuknya.
Semoga bermanfaat 🙂
kak mau tanya , kenapa Banyaknya k itu sebaiknya merupakan angka ganjil? tidak menggunakan angka genap ?Minta tolong butuh jawaban alasannya kak🙇
Hai Lala,
Tidak harus ganjil, lebih tepatnya k sebaiknya bernilai 3, 4, 5, dst, angka 2 mempunyai peluang besar mendapatkan frekuensi sama, misal k =2 (misal A,B), knn harus meningkatkan nilai k menjadi k = 3 (misal A,B,A), diperoleh output A,
Jika set 4, peluang frekuensi sama lebih rendah dari 2, tapi masih cukup tinggi, misal k = 4 {AABB,ABAB,BABA},maka nilai k harus ditingkatkan lagi
Semoga bermanfaat 🙂
Sebenarnya ini lebih ke efisiensi penggunaan resource komputer untuk menghitung KNN
jadi untuk penjelasan yang singkat bagaimana ya kak mengenai pertanyaan seperti diatas?
"Untuk menghindari frekuensi data kembar, yang secara langsung meningkatkan efisiensi".
Semoga membantu 🙂
Kak saya punya judul implementasi metode k-nn untuk prediksi penjualan handphonde,apakah bisa menggunakan metode knn?
Hai kak Yulia, itu implementasi-nya bagaimana ya ?
Kak Mau bertanya untuk data latih pada knn apakah bisa ditambahkan atau bisa di ubah?
Hai Kak Ama, data latih bisa diubah atau ditambah, bergantung kasus dan tujuan yang kakak aplikasikan
Semoga membantu 🙂
kak mau tanya dong kak klw begini cara penyelesaian nya gimana ya kak
Dengan menggunakan KNN dengan K = 5 dan distance antar data menggunakan euclidean, tentukan kelas data yang ke 10
terima kasih kak. materi yg dijelaskan membantu sekali untuk memahami knn :))
tapi maaf kak, boleh nanya? untuk judul "prediksi peserta mata kuliah", kira kira lebih cocok menggunakan knn atau naive bayes ya kak? mohon pencerahan nya kak, masih bingung 🙁
Hai Diah, saran saya lebih baik ditest keduanya...
kedua algoritma mempunyai performa yang berbeda-beda tergantung dimensi data dan kasus yang diaplikasikan
Namun untuk kemudahan dalam pengaplikasian, menurut saya KNN merupakan metode yang cocok
Semoga membantu 🙂
kak mau nanya, saya punya judul "prediksi peserta mata kuliah" cocok gak ya kalo pake metode knn? lebih cocok menggunakan knn atau naive bayes ya kak menurut kakak. mohon pencerahannya kakk
halo kak ingin bertanya. bagaimana car amenghitung dimensi dat aya kak? kalau datanya berupa sinyal suara bagaimana car amengetahui dimensi datanya
Selmat pagi kak, mau nanya kalo pemrogaman K-NN setelah PCA tnpa ada dimensi gmana ya kak?
Soalnya dta saya dari PCA tidk ada dimensi
"Penentuan nilai k dipertimbangkan berdasarkan banyaknya data yang ada dan ukuran dimensi yang dibentuk oleh data." maaf kak mau tanya, yang dimaksud banyaknya data dan ukuran dimensi itu yang mana ya kak jika pada contoh diatas?
Halo kak,saya ingin bertanya la kak, untuk penentuan nilai k itu cara ny gimana sih k, bisa bebas persepsi kita sendiri atau ada ketentuan ny langsung kk?trimakasih
Halo Kak,misal kita memiliki dara training sebanyak 210 data, data testing sebanyak 215 data,untuk nilai k yg cocok lebih bagus kita gunakan sebaiknya nilai k berapa ya kk, trimakasih🙏🙏